C-Eval
大语言模型的多层次多学科中文评估套件

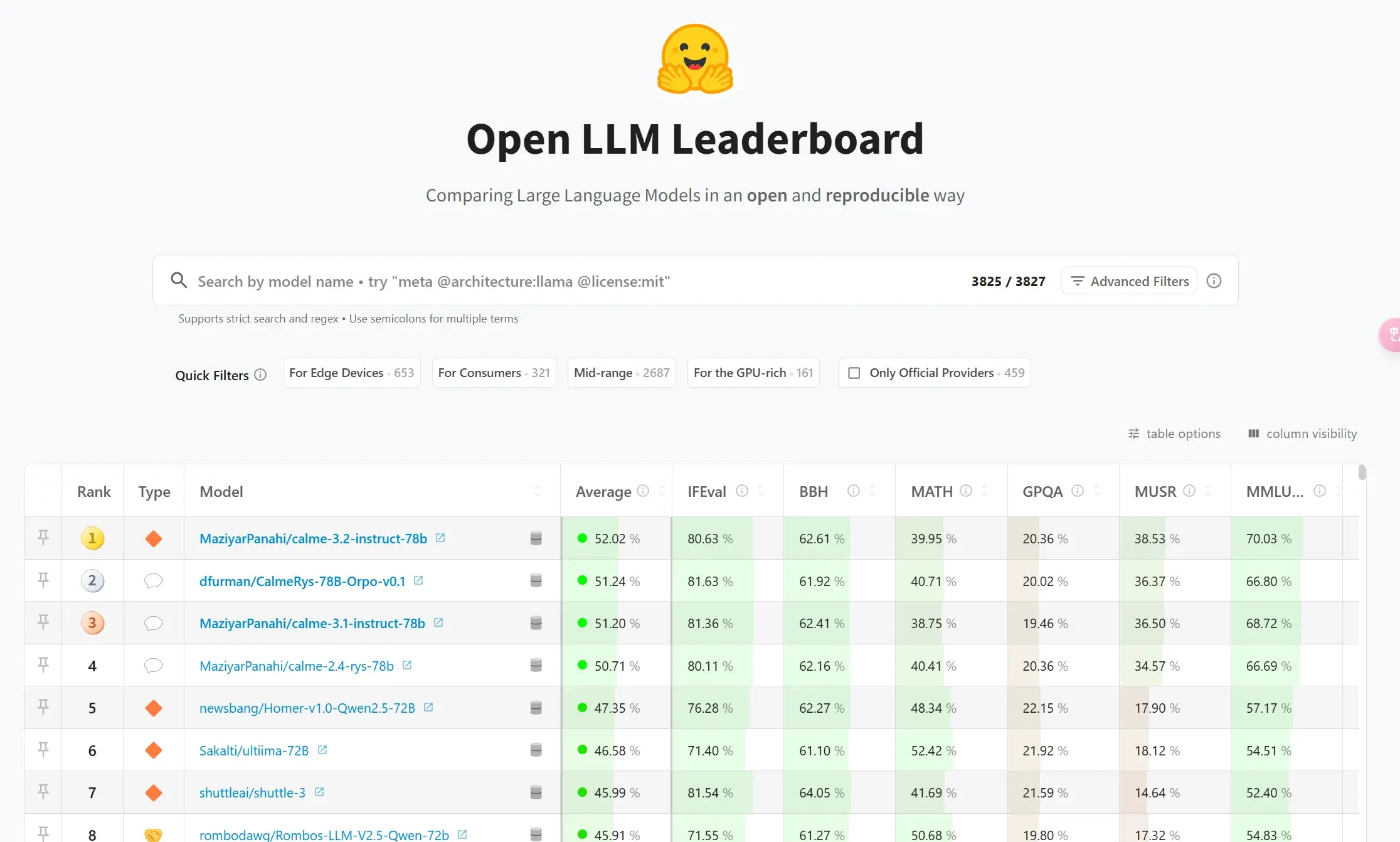
Open LLM Leaderboard (开源大模型榜单)专注于评估开源大模型的综合能力,涵盖知识理解、逻辑推理、数学计算、指令遵循等核心任务。其评测框架基于 Eleuther AI 语言模型评估工具,通过统一的标准对模型进行多维度测试,确保结果的可比性。
自发布以来,榜单已成为业界衡量模型性能的“黄金标准”,吸引了超过 200 万独立访问者,并推动了 Meta Llama、阿里通义千问等顶尖模型的迭代
2025年2月11日消息,榜单显示,其排名前十的开源大模型全部是基于阿里通义千问(Qwen)开源模型二次训练的衍生模型。