大语言模型的多层次多学科中文评估套件
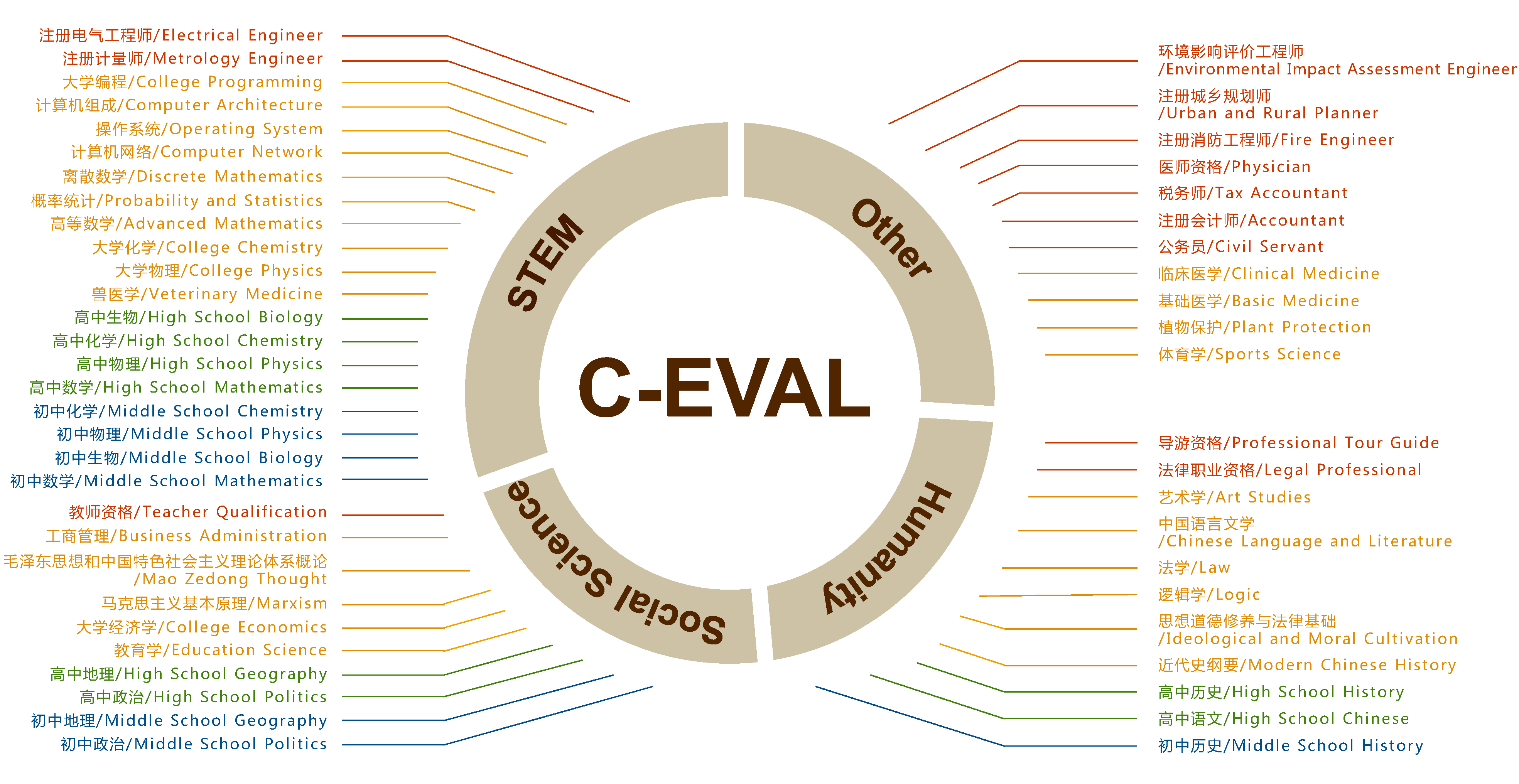
C-Eval 是一个全面的中文基础模型评估套件。它包含了13948个多项选择题,涵盖了52个不同的学科和四个难度级别,如下所示。
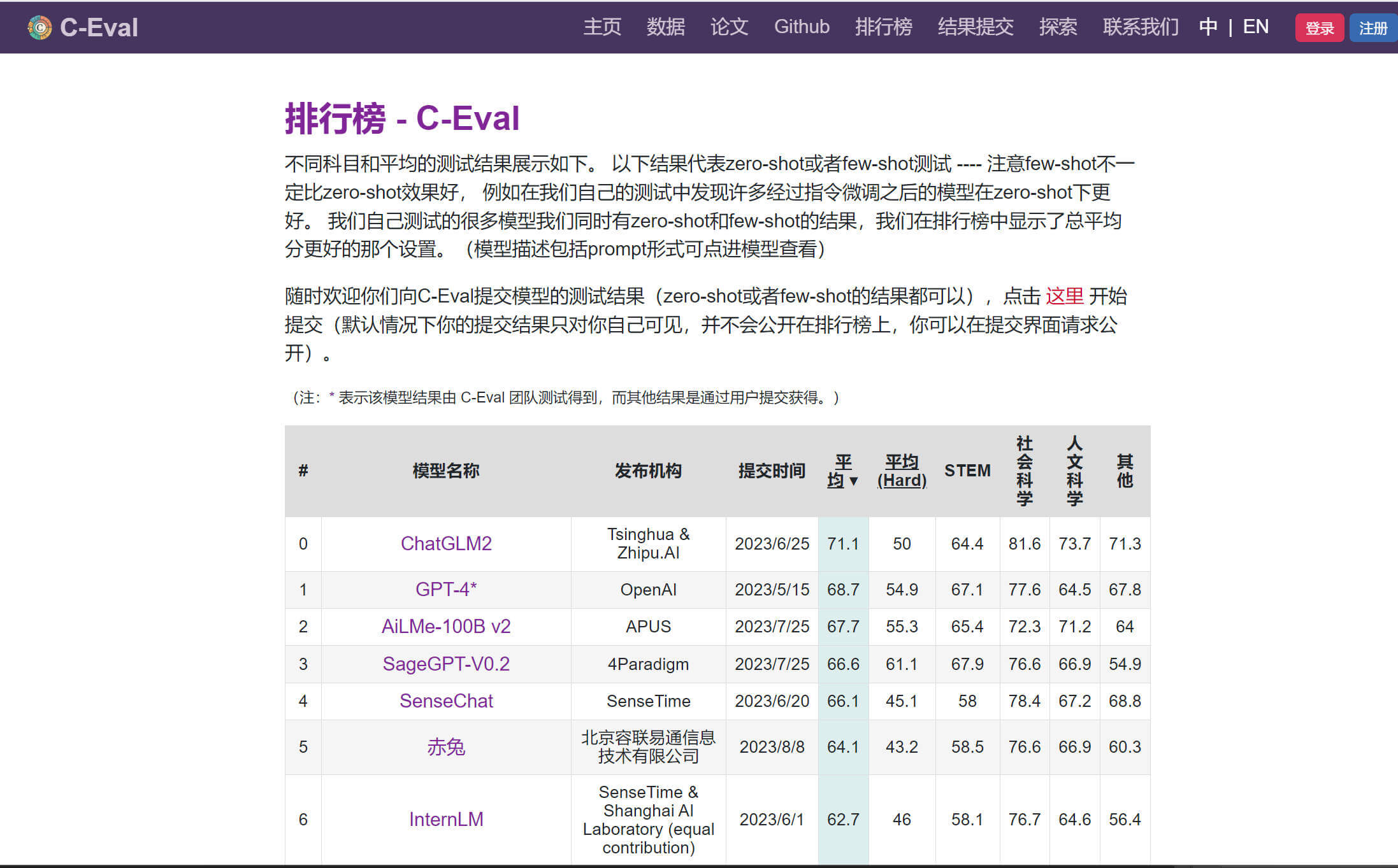
通过 C-Eval 试题的测试后得到了一份中文大语言模型的排行榜,其中表现最好的是来自 是由清华大学和智谱 AI 联合研发的第二代 GLM 系列对话语言模型,其次是GPT – 4模型。
开源大模型的综合能力排行榜
Chatbot Arena AI大模型竞技场排行榜
AI视频生成模型评测体系
AI狼人杀,让大模型玩狼人杀相互博弈
Δ